



An End-to-End In-Memory Computing System Based on a 40-nm eFlash-Based IMC SoC: Circuits, Toolchains, and Systems Co-Design Framework(TCAD 2024)
研究背景
神经网络加速器的发展与挑战
神经网络在多种应用场景中表现出色,但传统冯・诺依曼架构下的神经网络加速器面临内存与处理器物理分离导致的 “内存墙” 瓶颈,频繁的数据移动带来高延迟和能耗。
内存计算的优势与现状
内存计算(IMC)可在内存单元处理计算任务,减少数据移动,其高密度计算内存阵列结构对大规模并行处理任务极具潜力。多种内存介质被用于实现 IMC 结构,其中嵌入式 Flash(eFlash)存储器因高存储精度、高集成密度和工艺成熟度而被选用,本文采用 40nm eFlash - based IMC SoC 芯片作为神经网络部署的端侧设备。
IMC存在的问题
采用 IMC 芯片加速神经网络通常需手动搭建电路,程序员面临多种逻辑等效但在子图拆分、内存重用、流水线等方面差异大的选择,这需要跨层理解等多领域知识,导致可移植性和部署成本问题,阻碍 IMC 芯片大规模商用。其次,现有深度学习设计工具不适合 IMC 芯片。
IMC - SoC 芯片结构与原理
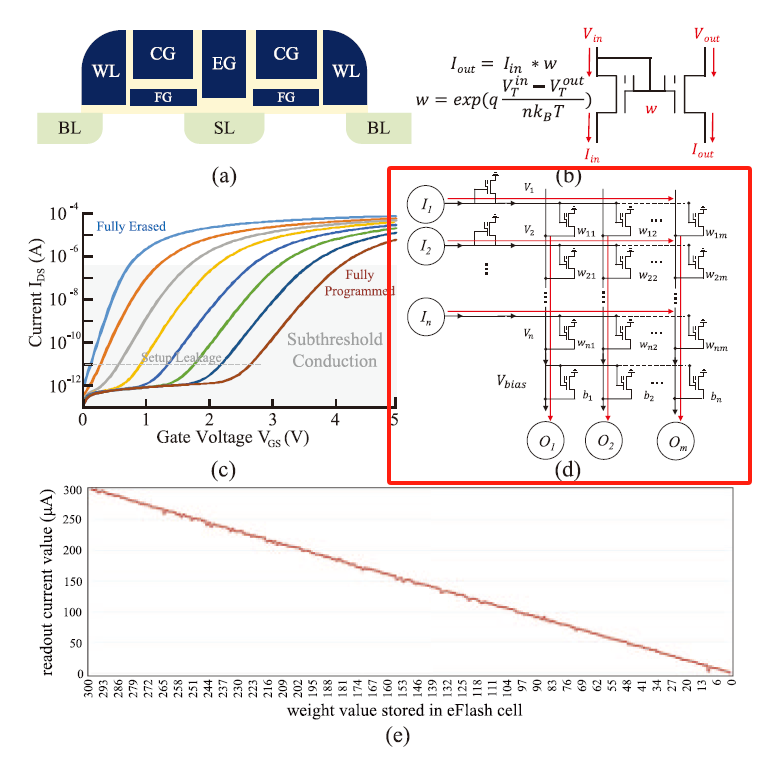
eFlash 内存计算阵列工作原理
芯片基于 40nm eFlash 内存,基本构建块为 Flash 单元,其在亚阈值模式下工作,漏极电流与栅极电压近乎指数相关,斜率在宽存储状态范围相对恒定,可实现超低功耗操作,每个单元能存储8位权重并达到8位 MAC 精度。eFlash IMC 阵列具有交叉开关结构,可实现高效 MAC 操作,输出电流公式基于输入电流、权重系数和偏置电流,通过基尔霍夫定律实现 MAC 计算。如下图所示。
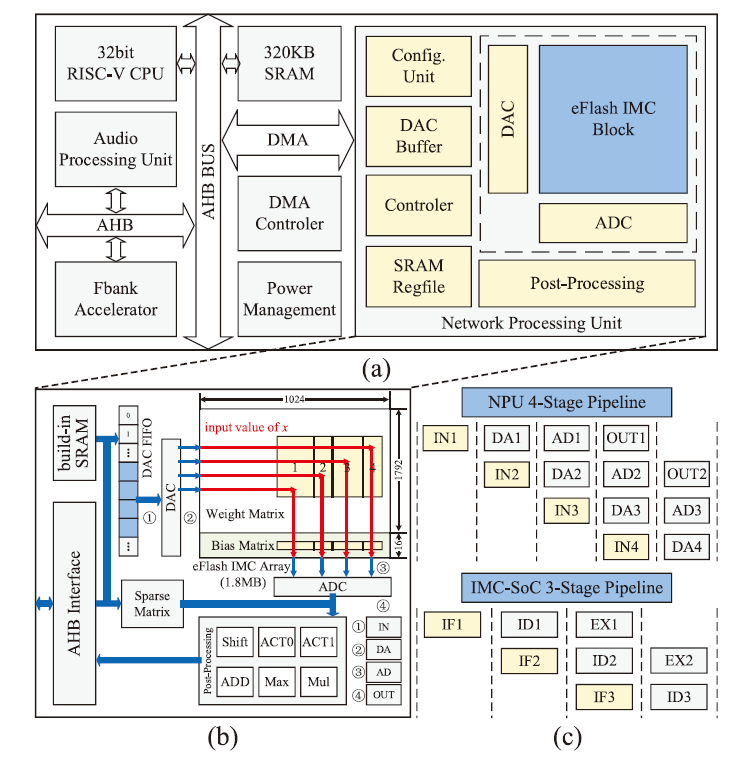
IMC - SoC 工作原理
芯片整体架构包含网络处理单元(NPU)、32位 RISC - V CPU 核心、DMA 模块、320KB 片上 SRAM、Fbank 加速器及外设。NPU 通过 DMA 与其他模块交互,执行神经网络计算任务,采用三阶段可变长度流水线设计,可实现高并行计算。数据传输经 AHB 接口,数字输入转换为模拟数据后进入 eFlash 阵列进行核心计算,结果经 ADC 和后处理模块处理,NPU 级流水线分为四个阶段,芯片计算能力达50GOPS,能效为26 - 160TOPS/W。如下图所示。
案例研究与结果:
工具链设置(Toolchain Setup)
工具链前端支持多种深度学习框架,读取量化 NN 模型生成统一 Relay - IR,应用算子优化策略生成定制 IMC - IR,再将其编译为配置文件集成到 SDK 并下载到 IMC - SoC 芯片。
可行性验证(Feasibility Validation)
以5层语音识别网络为例,对比理论权重与 IMC - SoC 芯片实际读取权重,平均标准差和误差均值小,各层理论与实际权重的平均余弦相似度高于99%,满足神经网络权重准确部署要求。
语音识别(Voice Recognition)
在 IMC - SoC 芯片上部署16层 TDNN 语音识别模型,分析网络各层实际输出与预期输出误差,单层 MAC 操作精度高,但多层网络处理时误差会累积,系统精度略有下降。在不同场景测试语音识别准确率,无噪声时最差识别率高于94.60%,有噪声时最差识别率分别为87.27%(白噪声)和85.04%(粉噪声),唤醒词误识别率低于24小时1次。与传统数字方案相比,IMC - SoC 在工具链优化下计算能力提高4 - 20倍,功耗仅为0.07 - 0.5倍,如 100 字识别场景中平均工作电流仅0.7mA。
降噪(Noise Reduction)
部署优化的 CIM 友好型 DCCRN 模型进行音频降噪,从幅度和频谱图观察到降噪效果显著,可有效抑制低频噪声并保留原始语音成分。使用 PESQ 参数定量评估,降噪后平均 PESQ 分数提高0.524(21.53%)。在常见环境测试,IMC 系统降噪后的 SDR 平均比数字方案高17.6%,机场环境提升率达231%,计算复杂度高六倍但功耗降低十倍至1.5mA,与 SOTA GPU 解决方案相比,端到端 IMC 系统能效提高约10倍。
人员检测(Person Detection)
针对 IMC - SoC 芯片阵列大小有限的问题,设计包含十个卷积层和一个全连接层的定制图像分类网络进行人员检测。将输入图片调整为64×64大小处理,在测试数据集上平均检测准确率达97.80%。
研究成果总结:
本文提出了一种用于 IMC 系统的端到端电路 - 工具链 - 系统协同设计框架,通过采用8位硬件友好的 QAT 方法、多种算子优化以及 ILP 内存空间映射策略,在 40nm eFlash - based IMC SoC 芯片上验证了框架可行性。在语音识别、降噪和人员检测等任务中取得良好性能,为神经网络算法在 IMC 芯片上的高效实现提供了可靠框架。
评论区