



RDCIM: RISC-V Supported Full-Digital Computing-in-Memory Processor With High Energy Efficiency and Low Area Overhead (TCAS-I)
本文介绍一种支持 RISC-V 指令集的数字存算一体处理器(RDCIM),该处理器旨在解决传统存算一体(CIM)在能效和面积开销方面的问题,通过多种创新设计实现了高能效和低面积开销。
研究背景
存算一体应用场景与需求
深度神经网络(DNN)在多领域广泛应用,其中包含大量乘累加(MAC)运算。为满足 MAC 运算高并行性度的需求,多种冯·诺依曼架构 AI 加速器被提出,但其计算与存储单元分离导致“内存墙”瓶颈。
数字存算一体技术及挑战
CIM 可减少数据移动,模拟 CIM(ACIM)虽能效高但精度有限,数字 CIM(DCIM)可避免模拟CIM问题,却面临高功耗和高面积开销的挑战。具体表现为加法器树功耗高,支持多精度计算需额外增加电路面积,输入缓冲区采用寄存器导致面积开销大。
RDCIM 架构
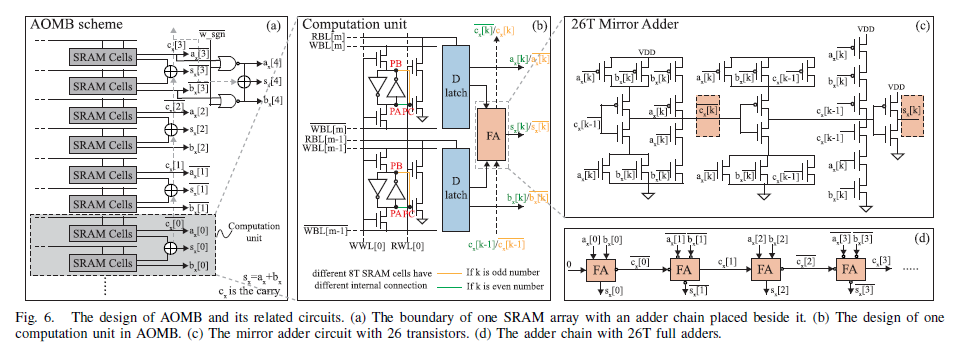
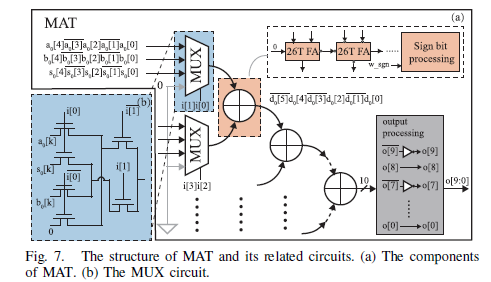
AOMB方案与MAT方案
AOMB 通过预处理权重数据减少数字计算电路负担,采用 26T 镜像加法器并优化 SRAM 单元结构。MAT 用于实现乘法和累加,第一级由多路复用器(MUX)组成,可降低功耗。AOMB 与 MAT 协同工作,显著降低了功耗。如下图所示。
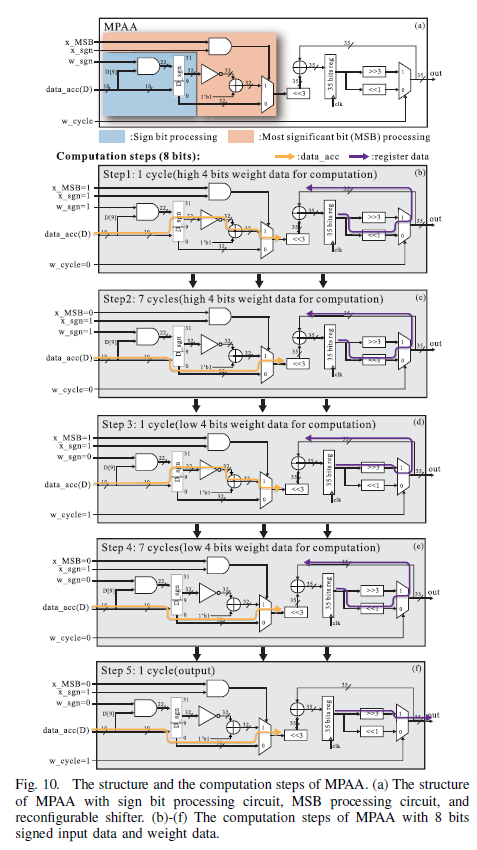
MPAA方案
MPAA 支持在 DCIM 内部进行多精度计算,通过配置信号灵活调整计算精度(4/8/12/16 bit)。与传统方案相比,MPAA 减少了额外电路带来的面积开销,提高了计算灵活性。如下图所示。
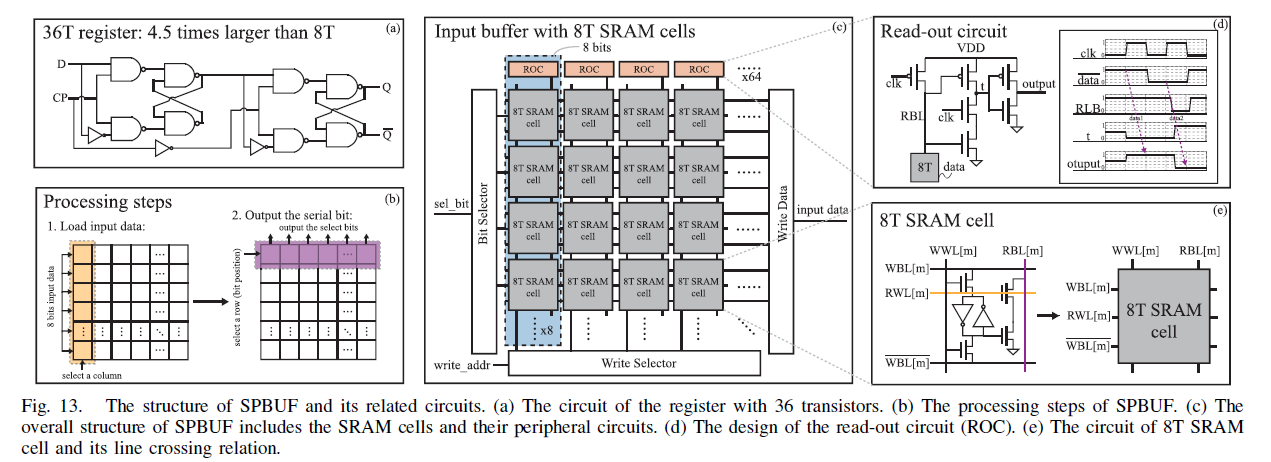
SPBUF方案
SPBUF 由 64 列 8T SRAM 单元组成,通过写选择器、位选择器和读出电路实现数据输入输出。与基于寄存器的输入缓冲区相比,SPBUF 面积开销降低了3.12倍,提高了存储密度。如下图所示。
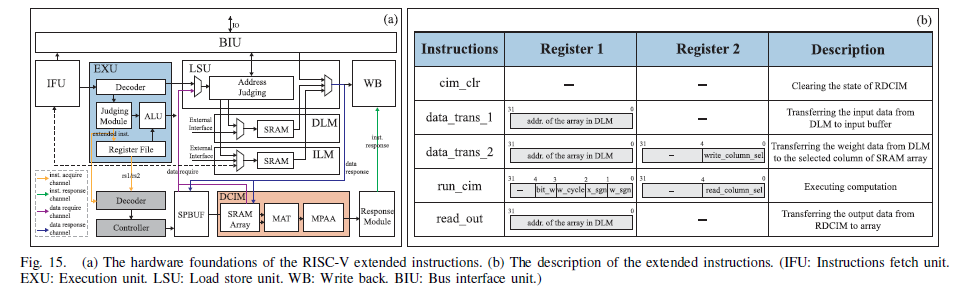
RISC-V 扩展指令
RDCIM 引入 RISC-V CPU,通过扩展指令紧密耦合 CPU 与 DCIM,控制 DCIM 状态。扩展指令包括 cim_clr、data_trans_1、data_trans_2、run_cim 和 read_out,分别用于复位 DCIM、传输输入 / 权重数据、执行计算和传输结果,提高了计算效率。如下图所示。
实验结果
性能评估
采用 55nm CMOS 技术制造的 64KB RDCIM 宏,在 200MHz 时钟频率下,4bit精度时能效为66.3 TOPS/W,8bit精度时为16.6 TOPS/W。与传统 DCIM 相比,采用 SPBUF、MPAA 和 AOMB 等特性后,功率效率和面积效率(PEPA)显著提高,RISC-V 指令控制也提升了计算效率。
神经网络模型评估
使用 ResNet-10 和 ResNet-18 在芯片上进行推理测试,RDCIM 宏在不同精度下实现了较高的能量效率,层效率范围为 27.97 TOPS/W 至 65.28 TOPS/W,量化误差导致神经网络推理精度有所下降。
能量和面积分解
在能量分解中,加法器树占 DCIM 主要能量的65%,与相关工作相比显著降低;在面积分解中,SRAM 阵列占78.1%,采用 MPAA 后累加器仅占3.6%。与其他先进的存内计算设计相比,RDCIM 在能效、阵列大小和灵活性方面具有优势。
研究成果总结
RDCIM 通过创新架构和优化设计,在存内计算领域取得了显著成果,为 DNN 等人工智能应用提供了更高效、灵活的计算解决方案。
评论区